我处理OutofMemoryErrors报错的五种姿势
Posted on
我使用Grafana创建可视化图表,它能向我展示银行对账单转换器的各种业务和性能指标。其中,我创建了一个图表,它能跟踪服务器返回给客户端的内部服务器错误数量。我是这么写的,每当有一个500报错发送到客户端时,我就向数据库中写入一条记录。这个图表对于解决我没有预料到的bug非常有帮助。上周四香港时间凌晨12:55,我的服务器开始抛出Java臭名昭著的OutofMemoryErrors报错。
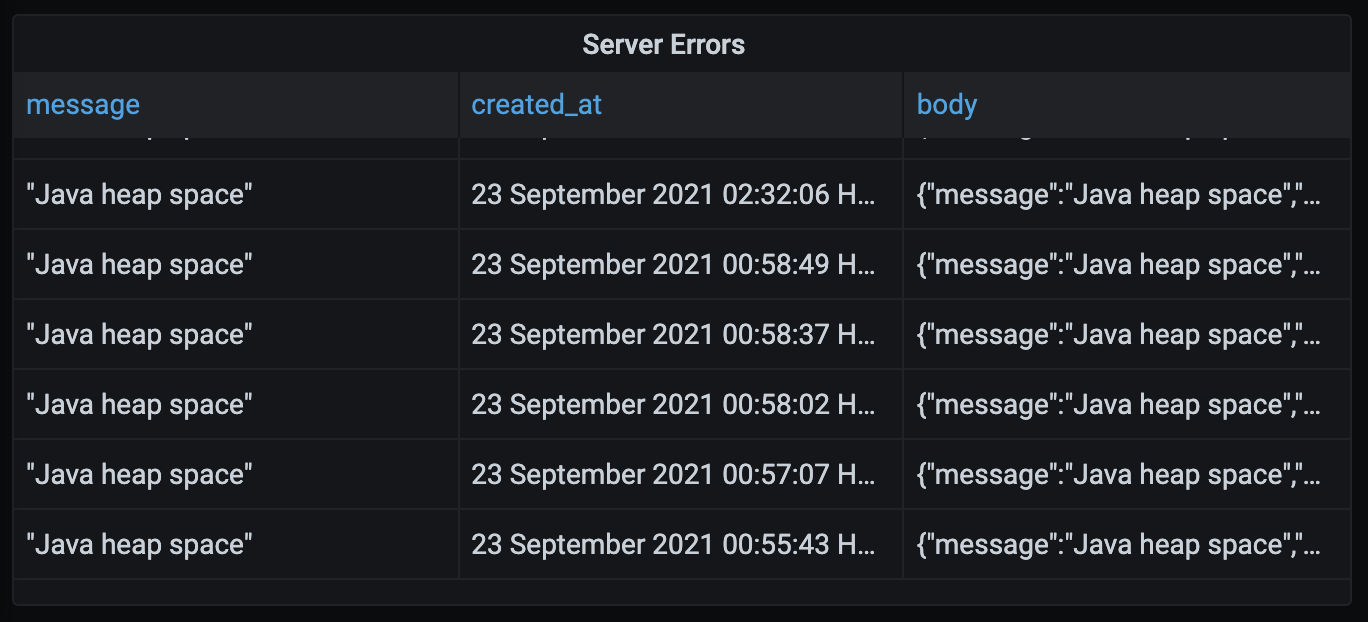
{
"message":"Java heap space",
"errorType":"UNKNOWN",
"cause":{
"type":"OutOfMemoryError",
"detailMessage":"Java heap space",
"stackTrace":[]
}
}
几个月前,我遇到了一些类似的错误,我通过升级服务器实例内存来解决,从1 Gb升级到了4 GB。那时我在我的服务器上运行tesseract,用以OCR识别基于图像的PDF。Tesseract使用了相当多的内存,所以我觉得我需要升级服务器的内存。我最近用亚马逊的textract替换了tesseract,所以我不再需要额外的内存来处理OCR图像。当我上周看到这些报错时,我想“难道我服务器上的4 GB内存快用完了?4 GB肯定能处理一个PDF文件了”。所以我决定优化我的代码,而不是通过投入更多的硬件来解决这个问题
1. 修复UI问题
当用户上传PDF并按下转换按钮时,UI将移动到 /converted 页面。 在这个页面中,UI将调用一个API,它会尝试自动检测PDF中的转账数据。 如果该API未能找到转账数据,则UI将移动到 /previewPDF 页面。 在此页面中,用户可以选择要提取的区域。但这里有一个小bug,导致出现下图中的状态。
![]()
下面的四个转账显示了用户在三秒钟内调用转换API四次。他们为什么要这么做?我花了一段时间才弄明白,但我最后还是弄明白到底发生了什么:
1. 用户上传一个PDF文件
2. 用户点击转换按钮
3. UI 带他们来到了 /converted 页面
4. API说它不能自动查找到转账信息
5. UI 带他们来到了 /previewPDF 页面
6. 用户按下返回按钮, UI 带他们来到 /converted page
7. 返回第#4步
大致上是这样的,用户希望返回到根页面,但UI最终会将他们带回到预览PDF页面。
之前
if (error.errorType === 'FAILED_TO_FIND_TRANSACTIONS') {
router.push('/previewPdf?uuids=' + uuid)
return
}
之后
if (error.errorType === 'FAILED_TO_FIND_TRANSACTIONS') {
router.replace('/previewPdf?uuids=' + uuid)
return
}
这会将历史堆栈中最新的URL替换为 /previewPdf,这意味着用户会被跳转至根页面而非 /converted 页面。用户会获得一个更好的体验,也减少了向服务器调用API的次数,更少的API调用意味着更少的内存使用,理论上这一会有助于降低OutofMemoryErrors报错的频率。
2. 优化文件上传API
修复UI后,我希望减少API调用时分配的内存量。我做的第一件事是访问开发环境,疯狂地在UI中单击以触发大量API调用。我通过这样的操作触发了OutofMemoryError错误。这个测试有点不公平,因为开发服务器只有1 GB的内存,而生产环境服务器却有4 GB。但有趣的是,我在上传文件时能触发这个错误。我吃了一惊,因为文件上传API的过程并不复杂当用户上传文件时,会发生以下情况:
- 验证该文件,确保它是PDF
- 读取文件并将其分成两类,基于文字的还是基于图像的
- 这样做是因为基于图像的文档需要进行OCR操作
在file_mapping表中创建一条记录,将uuid与文件名链接起来我有一个文件上传API的测试用例,我用Async Profiler进行测试。通过阅读报告,我发现我的处理程序占用了167 MB内存,从PDF中提取文本的代码占用了144 MB。这么大的内存占用量非常不可思议。


CharacterAndBoundParser.stripPage() 返回页面上所有字符的颜色、字体、旋转角度和边界框。 在上传阶段,我只需要知道文档是否有文本,一旦代码包含了一个字符,它可以说“是的,它有文本”,然后就停止程序。所以我写了一个这样的类。
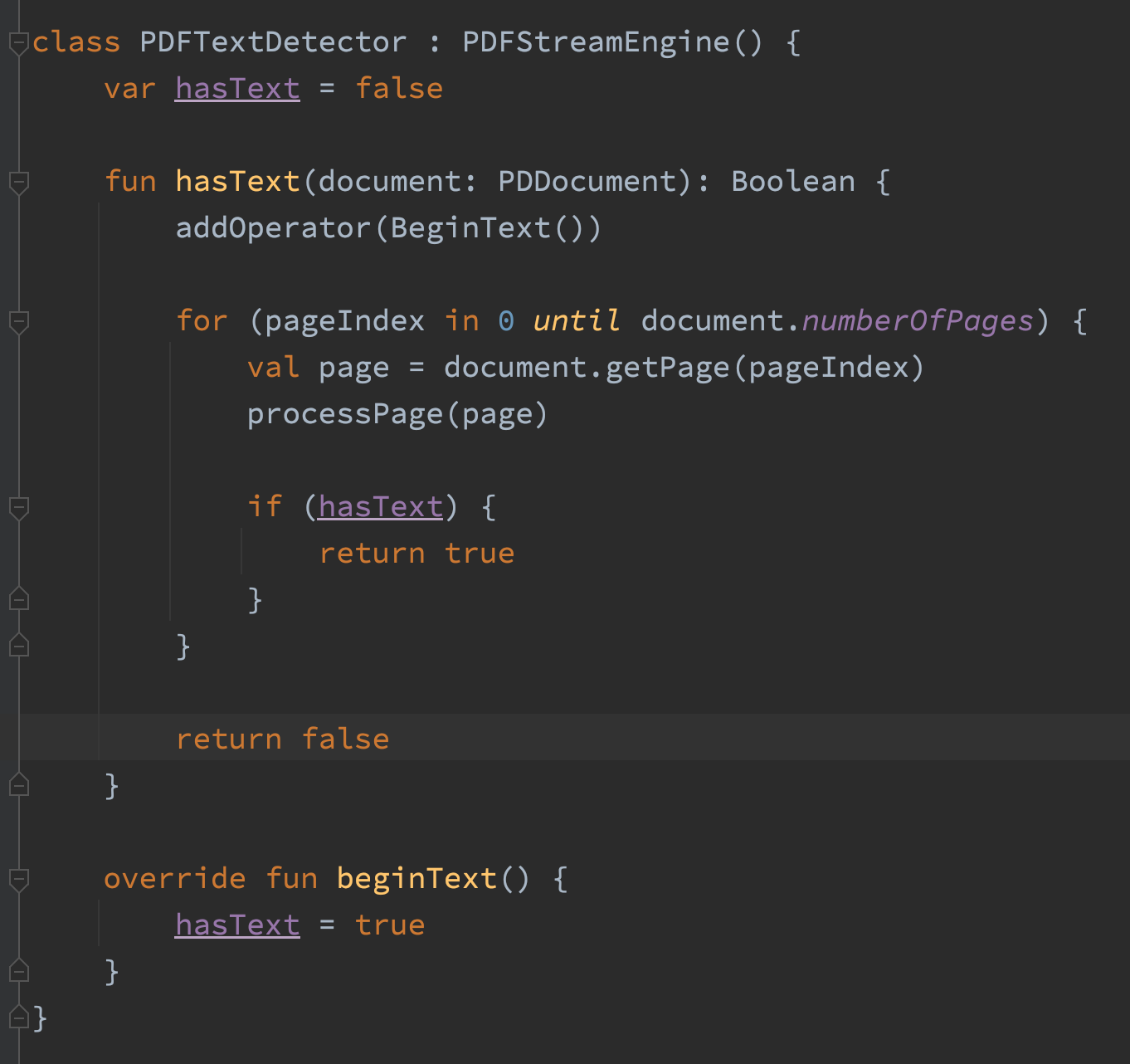
修改之后,整个文件上传过程占用了5 MB,这意味着我们所占用的内存比以前少了97%。太棒了!

3. 优化PDF转换API
这个优化是最酷的,我很享受解决这个问题的过程。我在PDF银行对账单转换为Excel文件的代码上运行了性能分析器,查看是否存在大量内存占用。

getXRange()方法在处理232页的PDF文件时占用了3311 MB内存。这让我很惊讶,因为这段代码似乎没干啥事。
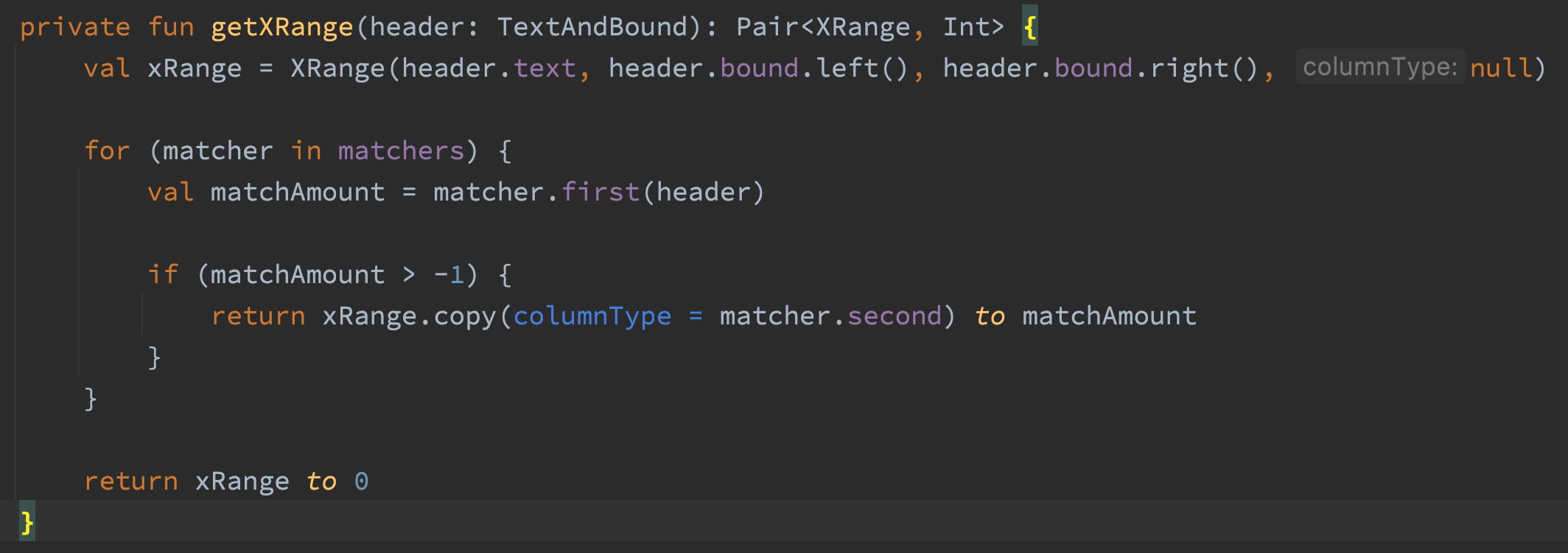
这段代码的第一行创建了一个XRange对象。只有当文本是转账头时,XRange对象才是必须要的。所以我修改了这段代码,让它只在文本匹配成功的情况下创建XRange。我又查了一遍分析器…它依旧占用了3311 MB内存。我尝试对getXRange进行修改,但都不能减少它的内存占用。 真是个绊脚石! 我进一步分析火焰图,发现有一个被所有匹配器调用的一个方法,其占用了GetXRange中100%的内存。

以下是 isEqualFromIndex() 方法的代码
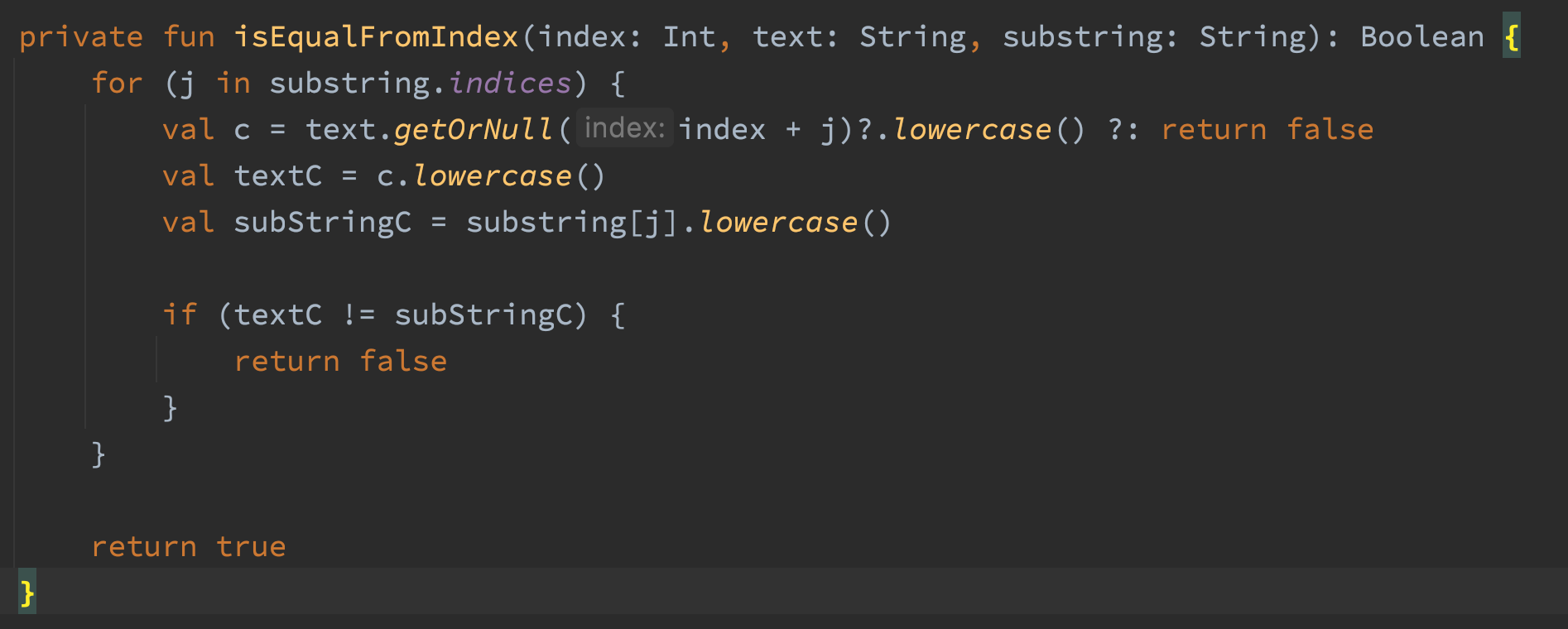
这段代码使用偏移量检查字符串中是否存在有子字符串匹配字符串。我编写这个方法的原因是为了在不占用内存的情况下检测字符串中不区分大小写的子字符串匹配。这段代码可以完成任务,但它占用了数吨的内存。这段代码中的顽皮部分是,它有调用三次lowercase()方法。其实只要调用两次就足够了,这是个愚蠢的问题。另一个问题是lowercase()方法返回一个字符串,这意味着我们在这个方法中循环分配了三个字符串。真恶心。我们不再使用lowercase()方法,转而使用Chars做对比任务。
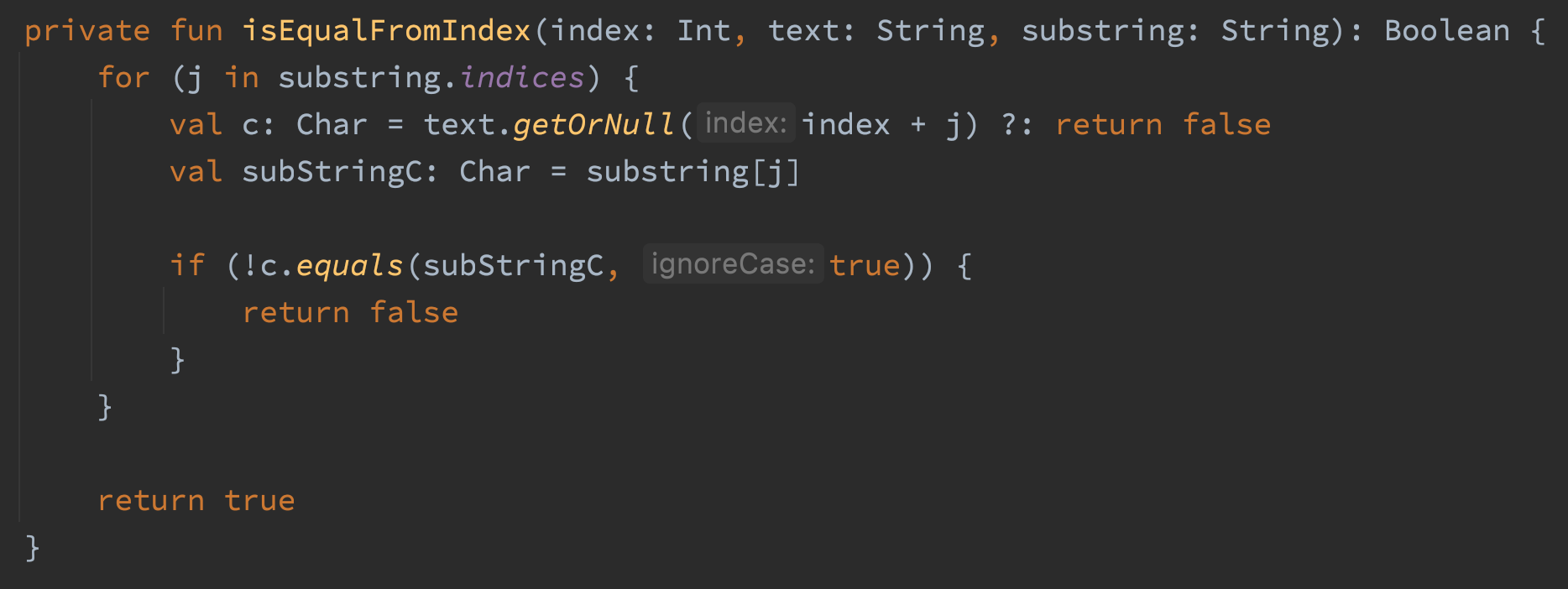
在此更改之后,getXRange占用了4 MB内存

我很享受修复这个问题,因为它只需要做很小的改动,并且修复这个问题并不需要任何有关应用程序知识。
4. 优化字符和边界框提取算法
在优化 #2 中,我们了解到characterandBoundParser.strippage()会占用大量内存。它继承的是PDFTextStripper,后者继承了LegacyPDFStreamEngine,后者继承了PdfStreamEngine。在PDFTextStripper和LegacyPDFStreamEngine中有很多代码,但我觉得没有它们我也能完成程序的功能。我创建了一个名为FastCharacterParser的类,它只继承了PDFStreamEngine
在分析之后,我了解到FastCharacterParser占用的内存要少得多,但是我测试用例时失败了,因为我缺少了PDFTTextStripper和LegacypDfStreamEngine中的一些重要功能。
组合字符
在我的测试文档中,有一个文档把一个六个字符的字“Office”编码成了五个字符“Office”,用 ‘fi’ (U+FB01) character 替换了两个字的“fi”。 我不知道它为什么这样做,但客户大概率不想要这样的结果。我使用一个Normalizer类解决了这个问题,该类将组合字符分解为基本字符。
if (0xFB00 <= c && c <= 0xFDFF || 0xFE70 <= c && c <= 0xFEFF) {
normalized = Normalizer.normalize(c, Normalizer.Form.NFKC)
}
粗体文本
有些文档通过稍微向左或向右移动复制的字符来将文本呈现为粗体。这意味着文本“hello”的粗体版本实际编码为“hheelloo”。我的一些测试用例用了这种方式呈现粗体文本。我通过按位置对字符进行排序,然后过滤掉相同和非常接近的字符来解决这个问题。
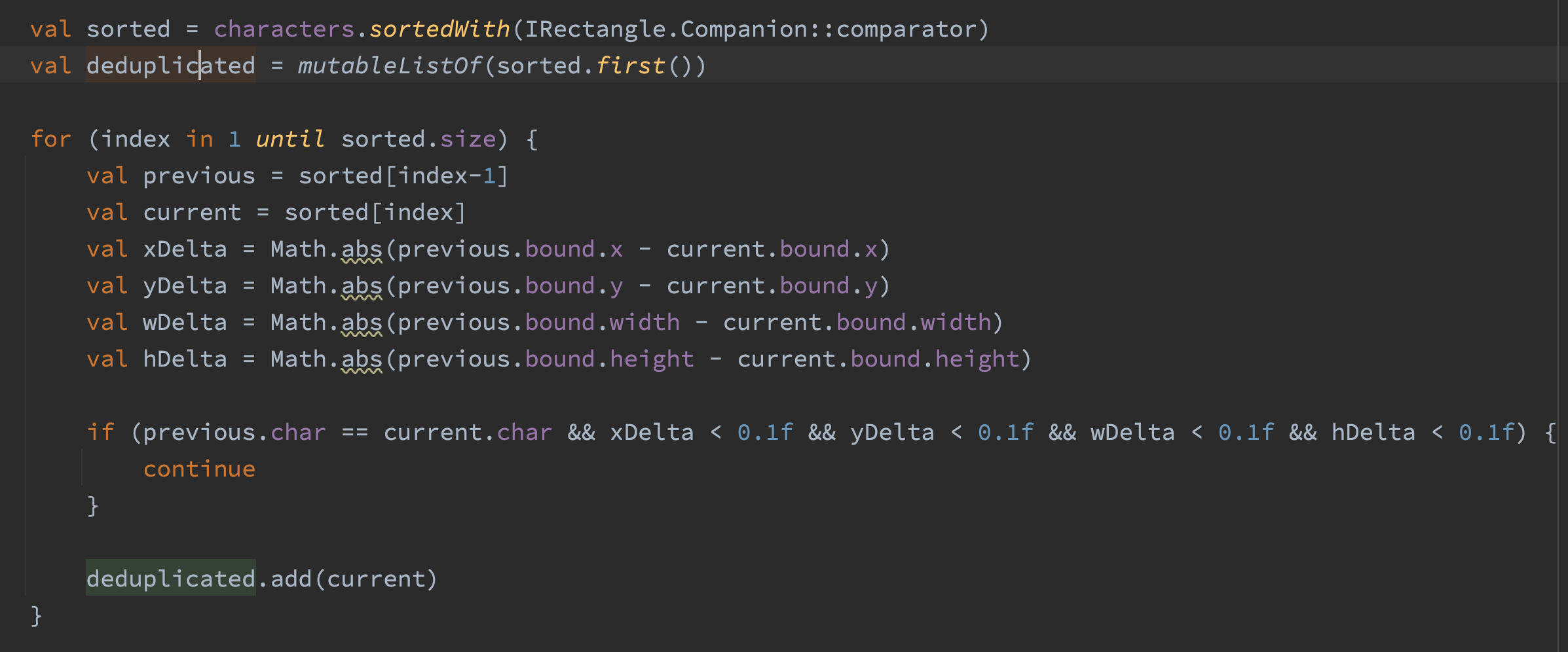
与CharacterandBoundParser相比,FastCharacterParser占用的内存要少20%。下降20%效果很明显,但我对这个结果略微有些失望。
5. 优化边界框的计算
处理大型文档时,FastCharacterParser的showGlyph()方法占用了482 MB内存,其中381 MB来自AffineTransform.createTransformedShape()方法。我们使用AffineTransformation将字体的坐标系转换为PDF文档的坐标系。
// 之前
var shape = at.createTransformedShape(rect)
shape = flipAT.createTransformedShape(shape)
shape = rotateAT.createTransformedShape(shape)
val bound = Rectangle.from(shape.bounds2D)
最初,我考虑将三个AffineTransformation组合成一个,然后调用createTransformedShape一次。这样可以将内存占用从381 MB减少到大约130 MB。不过,内存仍然占用了很多。我研究了下AffineTransform.java,发现了这个让人愉快的小技巧:
public void transform(float[] srcPts, int srcOff,
float[] dstPts, int dstOff,
int numPts)
这样代码看起来会更轻巧。我接着把字体的边界框分成两个点,调用transform方法,自己计算边框。 这是最终代码
// 转换长方形
val buffer = floatArrayOf(rect.x, rect.y, rect.x + rect.width, rect.y + rect.height)
at.transform(buffer, 0, buffer, 0, 2)
flipAT.transform(buffer, 0, buffer, 0, 2)
rotateAT.transform(buffer, 0, buffer, 0, 2)
// 计算转换后的长方形边界值
val minX = Math.min(buffer[0], buffer[2])
val maxX = Math.max(buffer[0], buffer[2])
val minY = Math.min(buffer[1], buffer[3])
val maxY = Math.max(buffer[1], buffer[3])
val bound = Rectangle(minX, minY, maxX - minX, maxY - minY)
最终showGlyph方法会占用95 MB内存,比以前少了大约387 MB。
结论
Async Profiler能生成的报告非常容易理解,很快就能找到代码中占用内存最多的方法。我所作的更改使得我的程序能应付更多的并发,这是上一版本的程序无法做到的。您可能会认为我这是在浪费时间,因为我的应用程序不会出现大量的并发流量,但我喜欢减少程序的内存占用,这才是最重要的事情。