PDF Tales - Extracting Text You Can't See
Posted on by Angus Cheng
A few months ago I got an email from a customer in Dubai asking me to help extract transactions from a PDF bank statement. This is pretty normal. I get about ten of these emails a day. I had a look at the PDF and thought:
“Damn, banks are even stupider than I thought.”
The statement was basically an excel file, exported out into a PDF. It’s so annoying when people do that, because most people would rather have the Excel/CSV file. Imagine the table is rendered in the PDF like this:

That would be pretty easy to extract. Sadly, it wasn’t in that format, it was in this format:
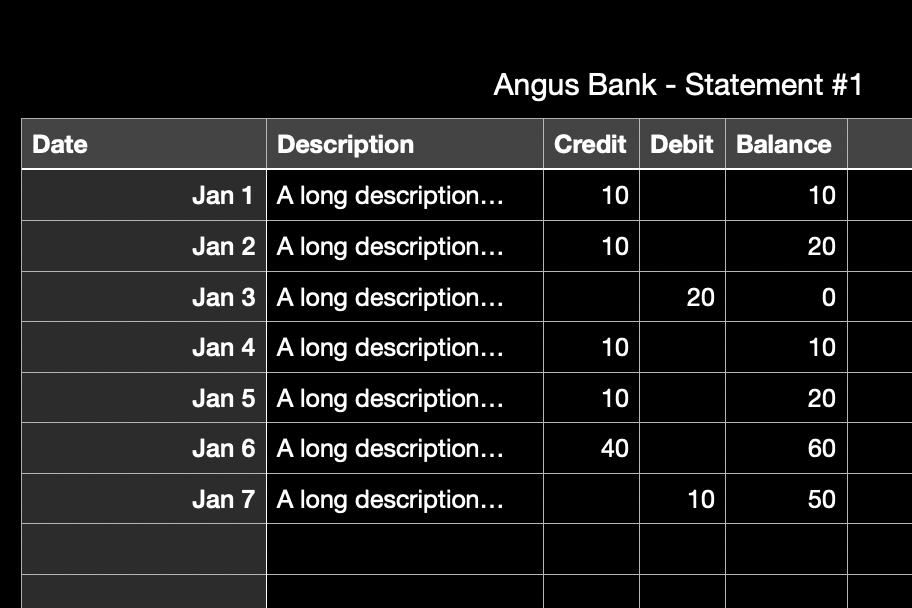
Still not too bad right? The description has been cut off, so our converter should just return cut off descriptions to the user. Except for one thing, the text elements of the description are being drawn “under” the Credit, Debit and Balance columns.
Bank Statement Converter works roughly like this:
- Try find text that look like the header of transaction table. Something like “Date”, “Description”, “Credit”, “Debit”, “Balance”
- Find the bottom of the table
- Get all the character elements within the table boundaries
- Group the characters into words
- Associate the words with headers, based on their position
- Render the table out to CSV.
A long description that ‘bleeds’ into the other columns messes with step four of my algorithm. This is because characters from the description, have bled into the Credit, Debit and Balance columns. These characters form into words, and they turn the Credit, Debit and Balance columns into nonsense.
Imagine the following row:
"Jan 1","A long description, the description needs to be long for the purposes of this story. Transaction ID 12873187238203","10","","10"
My code was rendering the row like this
"Jan 1","A long description, the description needs to be long for the purposes of this story. Transaction ID 12873187238203","th1e des0","cription","ne2ed0s to be long for the purposes of this story. Transaction ID 12873187238203"
Seems impossible to fix, how do I know which characters are description characters, and which characters are Credit, Debit or Balance characters? Quite the stumper.
Intro to PDF
I’ll introduce you to four PDF commands.
BT - Begin text
ET - End text
Tm - Set text matrix and line matrix
TJ - Show text allowing individual glyph positioning
Debugging
I decided to debug the PDF using PDFSnake. Looking at the PDF, I realised every cell of the rendered table started with a BT command and ended with an ET command. It also contained exactly one Tm command and exactly one TJ command. Here’s roughly how the PDF commands are laid out:
BT
1 0 0 1 80.304 616.78 Tm
[Jan 1] TJ
ET
BT
1 0 0 1 180.304 616.78 Tm
[A long description, the description needs to be long for the purposes of this story. Transaction ID 12873187238203] TJ
ET
BT
1 0 0 1 280.304 616.78 Tm
[10] TJ
ET
BT
1 0 0 1 380.304 616.78 Tm
[] TJ
ET
BT
1 0 0 1 480.304 616.78 Tm
[10] TJ
ET
The table is rendered top left, to bottom right, so you could write code like this:
val commands = extractPdfCommands(document)
val showTextCommands = commands.filter { it.endsWith("TJ") }
val index = showTextCommands.indexOfFirst { extractText(it) == "Running Balance" }
if (index == -1) {
throw Error("Kaboom")
}
val grid = Grid()
for (i in index until commands.size) {
val tableWidth = 6
val x = (i - index) % tableWidth
val y = (i - index) / tableWidth
grid[x][y] = extractText(commands[i])
}
return grid
That’s not the actual code I wrote, but I did exploit the property of the document to extract the data. The client was happy because I was able to get description data out of the PDF that you couldn’t even see.