PDFからテキストとバウンディングボックスを抽出する
Posted on by Angus Cheng
今回のブログ投稿のシリーズは銀行明細変換で以前説明をした続きになります。この投稿ではバウンディングボックスとその他の特徴に関するコードを説明します。大半のコードは下記から取り出してきました。 DrawPrintTextLocations and PDFTextStripper.
まず初めに、これを行うのは PDFBoxを使用してPDFファイルをアップロードする その後、一ページずつ処理をしていきます。PDFはメモリーがいっぱいになる事はない為、1ページずつ処理をしていきます。ほとんどの書類は10ページ以下ですが、稀に10,000ページ以上の書類も存在する為、このデータを一度にメモリー化するとアプリは直ぐにクラッシュしてしまいます。解析ページ法を使い、ページ内の特徴を抽出して、特性とバウンディングの対象リストが作成されます。
data class CharAndBound(
val char: Char,
val bound: Rectangle,
val color: Int,
val fontCode: Int,
val rotation: Int
) : IRectangle by bound
急速な—特性解析
急速な特性解析のクラスでのストリップページ法は特性とバウンディング対象のリストを引き戻す事について説明をしました。PFF Boxkからの延長となります。PDFストリームエンジンクラス and listens to the following events:
private fun setOperators() {
addOperator(ShowText())
addOperator(BeginText())
addOperator(Concatenate())
addOperator(DrawObject())
addOperator(Save())
addOperator(Restore())
addOperator(NextLine())
addOperator(MoveText())
addOperator(MoveTextSetLeading())
addOperator(SetFontAndSize())
addOperator(ShowTextAdjusted())
addOperator(SetTextLeading())
addOperator(SetMatrix())
addOperator(ShowTextLine())
}
PFDストリームエンジンは造形文字もあります。 造形文字 早急な特性解析のshowGlyph法では、特性とバウンディング対象の全てのプロパティを計算してくれます。
override fun showGlyph(
textMatrix: Matrix,
font: PDFont,
code: Int,
displacement: Vector
)
textMatrixパラメーターを使用して造形文字のページ内のローテーションと位置を決定する事が出来ます。又、造形文字の幅や高さを決定するのもバウンディングボックスのフォントを使って決定する事が可能です。いくつかのフォントにはバウンディングボックス情報が無い為、その様な状態が発生した際にはハードコードバウンディングボックスで対応できる事を願います。
val bbox = getBoundingBoxWithHackyFallback(font)
// advance width, bbox height (glyph space)
val xAdvance = font.getWidth(code)
val rectangle = Rectangle2D.Float(0f, bbox.lowerLeftY, xAdvance, bbox.height)
この時点で2Dの長方形が出来上がっていますが、‘書面スペース’ではなく’造形文字スペース’になっており、直ぐに分かる問題として、X座標がハードコードで0fとなってしまっています。 次のステップでこの長方形を造形文字スペースから書面スペースへ変換していきます。
val affineTransform = textMatrix.createAffineTransform()
// Transform the rectangle
val buffer = floatArrayOf(rectangle.x, rectangle.y, rectangle.x + rectangle.width, rectangle.y + rectangle.height)
affineTransform.transform(buffer, 0, buffer, 0, 2)
flipAT.transform(buffer, 0, buffer, 0, 2)
rotateAT.transform(buffer, 0, buffer, 0, 2)
// Calculate the bounds of the transformed rectangle
val minX = min(buffer[0], buffer[2])
val maxX = max(buffer[0], buffer[2])
val minY = min(buffer[1], buffer[3])
val maxY = max(buffer[1], buffer[3])
val bound = Rectangle(minX, minY, maxX - minX, maxY - minY)
上記のAffine変換はページのローテーションとページの高さによって形成される。PDFの出処はページの左下に掲載されているが左上にあった方が良いので、その場合はflipATが変えてくれる。
rotateATも同様に、バウンディングボックスの特性へのページローテーションを行ってくれる。ほとんどの書面のローテーションは0だが、ランドスケープの書面などは90か270のローテーションなどもある。ページには既に造形文字のバウンディングボックスが存在しているので、次にこのフォントコードは何の特性を表現するのかを見ていきましょう。
var unicode = font.toUnicode(code, glyphList)
if (unicode == null) {
if (font is PDSimpleFont) {
val c = code.toChar()
unicode = String(charArrayOf(c))
} else {
return
}
}
unicode = normalizeWord(unicode)
始めに、フォントのフォントコードの特性を取得します。ここでミスってしまい、フォントがSimpleFontである場合はフォントコードがユニコードとみなされ、特性へ変換されます。通常の方法として、構成されている特性のベースパーツを分けて変換していくのです。
The character ‘ff’ is encoded in UTF16 as FB00, normalizeWord breaks it up into two ‘f’ characters and returns the string “ff”.
if (unicode.length == 1) {
characters.add(CharAndBound(unicode.first(), bound, rgb, fontCode, rotation))
return
}
val startX = bound.left()
val width = bound.width / unicode.length
for (index in unicode.indices) {
val x = startX + (index * width)
characters.add(CharAndBound(unicode[index], bound.copy(x = x, width = width), rgb, fontCode, rotation))
}
通常は特性コードのストリングフォームは長いです。この場合、特性とバウンディングから成形し、特性のリストへ追加をします。ただし、‘ff’の様な複合文字の場合もあります。2つ以上の長い物であればユニコードが “ff” と表示されます。上記のコードはバウンディングボックスをストリング内の特性と共有します。例えば ‘ff’ のバウンディングボックスは[0,0,120,30]ですが、最初の ‘f’ を切り離すとバウンディングボックスは [0,0,60,30] になり、2つ目の ‘f’ のバウンディングボックスは [60,0,60,30]に変わります。縦書きの方がこれを無視して出来そうな感じがするのですが、このコードは縦書きだと上手くいきません
実際にやってみましょう。私がオンラインで見つけた [このPDF] (https://juventudedesporto.cplp.org/files/sample-pdf_9359.pdf) はバウンディンボックスを抽出し、各ページへ提出していきます。目的通り、正確に出来上がっています。

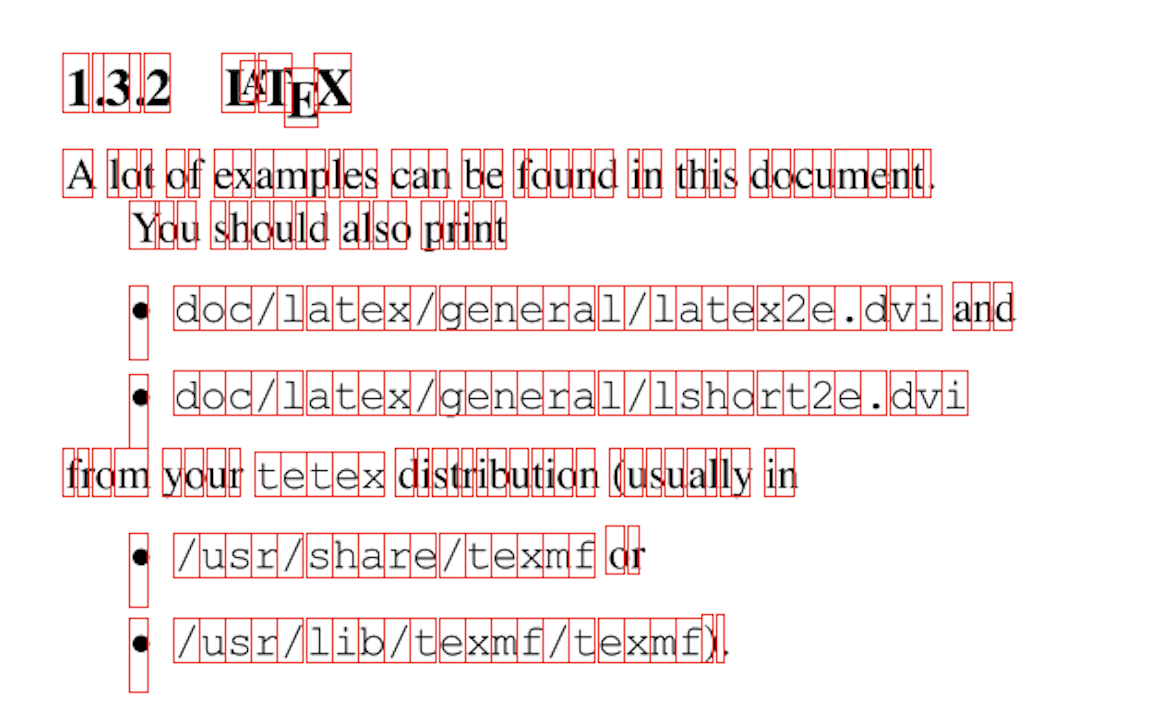
次回
パート2では特性とバウンディングリストをっ使用してどの様に取引表のヘッダーを確定するのかを説明します。