メモリ不足の5つの対応策
Posted on by Angus Cheng
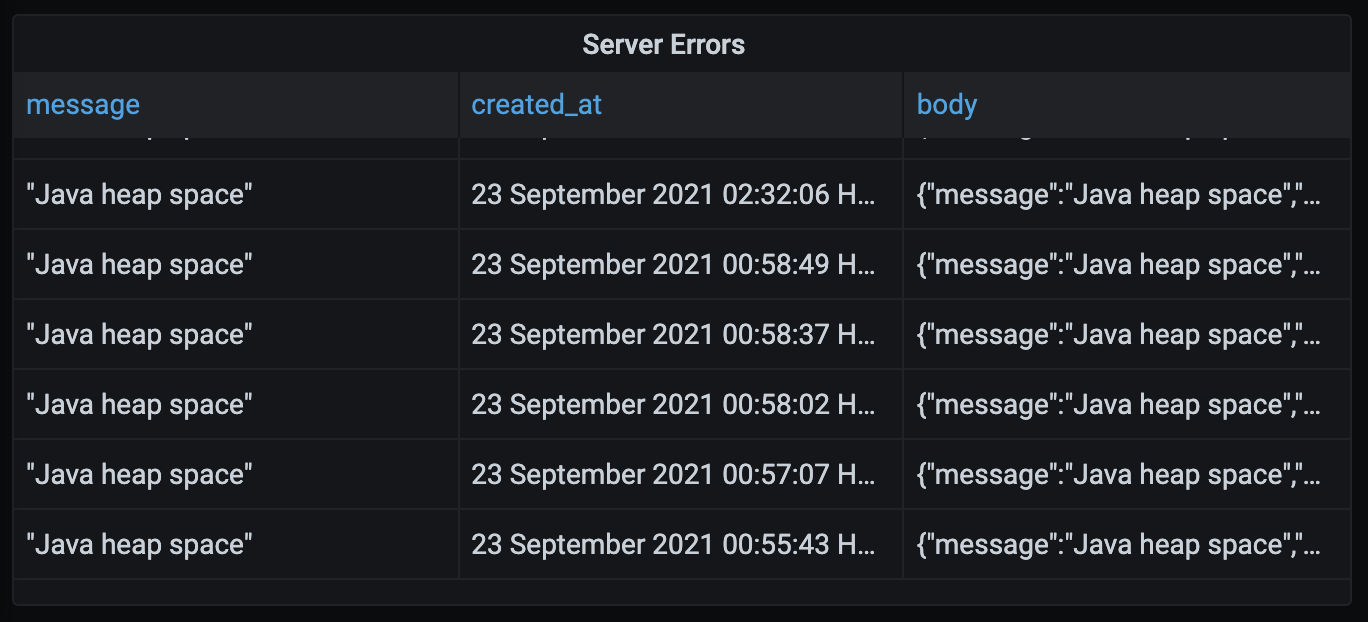
Grafanaを使用して色々な企業へ銀行明細変換の為のグラフやパフォーマンス指標などの作成を行っています。作成した内の一つはインターナルサーバーエラーが何回発生したかを追跡し、クライアントへ情報展開するものでした。記録をデータベースに書き込み、500以上になるとクライアントへ情報伝達をしました。この様なグラフがあると予想していなかったバグなどの対応にも便利となるのです。先週木曜日香港時間午前12:55によくJavaでは見られるサーバーからメモリ不足との警告が出始めました。
{
"message":"Java heap space",
"errorType":"UNKNOWN",
"cause":{
"type":"OutOfMemoryError",
"detailMessage":"Java heap space",
"stackTrace":[]
}
}
数カ月前に何度かこのエラーが発生し、この時は自分のサーバーを1 GBから4 GBへアップグレードしました。その時、私はtesseract OCR画像ベースのPDFをサーバーに取り入れていました。Tesseractは結構な量のRAMを使うので、RAM量の多いサーバーが必要だと思いました。最近tesseractをアマゾンのtextractへ変えたので、OCR画像の為のRAM追加分は不必要になりました。先週エラー表示が出た時、「サーバーが4GBなのになぜRAMが不足したのか?PDFを処理するには4GBあれば十分なはずだ」と思ったのです。ハードウェアにこれ以上の問題を与えるのではなく、コードをの効率的に利用しようと決断しました。
1. UIの問題解決
ユーザーがPDFをアップロードする際に変換ボタンを押すとUIは**/convertedのページへ飛びます。このページでUIがAPIを呼びPDF内の取引データを自動探知しようとします。もし、APIが取引データの探知に失敗っした場合、UIは/previewPDF** ページへ飛びます。このページではユーザーが抽出箇所を選択する事ができます。ここで下記画像の様な小さなバグが見受けられます。
![]()
下4つの取引はユーザーが3秒内にAPIへの変換を4回行った事が示されています。なぜこの様な事をしたのでしょうか?これを考えるのに少し時間が掛かりましたが、やっと何が起きていたのかが分かったのです。:
1. ユーザーがPDFをアップロードする
2. ユーザーが変換ボタンを押す
3. UIが変換ページへ切り替える
4. APIにて取引の自動探知失敗のお知らせが表示される
5. UIがPDFプレビューページへ切り替える
6. ユーザーが戻るのボタンを押すと、UIは変換ページに切り替わる
7. #4に戻る
基本的にユーザーは元々のページに戻りたがるので、UIは後々PDFプレビューページへ切り替えられます。この解決法は案外簡単です。
ビフォー
if (error.errorType === 'FAILED_TO_FIND_TRANSACTIONS') {
router.push('/previewPdf?uuids=' + uuid)
return
}
アフター
if (error.errorType === 'FAILED_TO_FIND_TRANSACTIONS') {
router.replace('/previewPdf?uuids=' + uuid)
return
}
これで、最後の経歴リストPDFプレビューの最後のURLが交換されます。これはユーザーは変換ページではなく、元々のページへ飛ばされてしまうという意味を持ちます。この方がユーザーにとっても良いし、何度もAPIのサーバーへのコールが低減されるという事です。APIのコールが少ないという事はRAM使用量も低減されメモリ不足になる頻度も減少するという事になります。
2. APIファイルアップロードの効率向上
UIの問題解決後APIがコールした際のメモリ量を低減したいと考えました。まず初めに私が行った事はDEV環境へ行き、APIコールを何度もする為にUI内で何度も何度もクリックを繰り返します。その後、メモリ不足エラーを表示させる事が出来ました。このテストはDEVサーバーのRAMは1GBしか無く、PRODサーバーは4GBある為、若干不公平になっています。面白い事にファイルをアップロードする際にエラーを押す事が出来たのです。ファイルをAPIへアップロードする際は色々な事が起きているので、これが出来る事自体驚きました。ファイルのアップロード後下記が起こりました:
-
ファイルがきちんとPDFになっているかの検証
-
ファイルがテキストベースか画像ベースかきちんと分類し読み込まれているか。画像ベースの書面はOCRになっていないとダメなので、この確認を行います。
-
ファイルマッピング表内のファイル名付のuuidへ記録を作成し、リンクさせます。
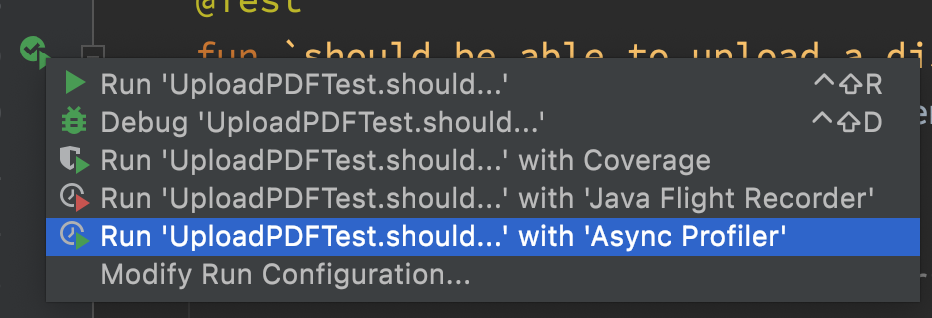
APIのファイルアップロードのテストケースは持っているので、[Async Profiler]へトリガーさせ、有効にしました。(https://www.jetbrains.com/help/idea/async-profiler.html) レポートを読んでいる時、ハンドラから167MB割り当てられ、PDFからテキストを抽出するコードに144MB割り当てられている事を発見しました。これは相当なRAM量です。


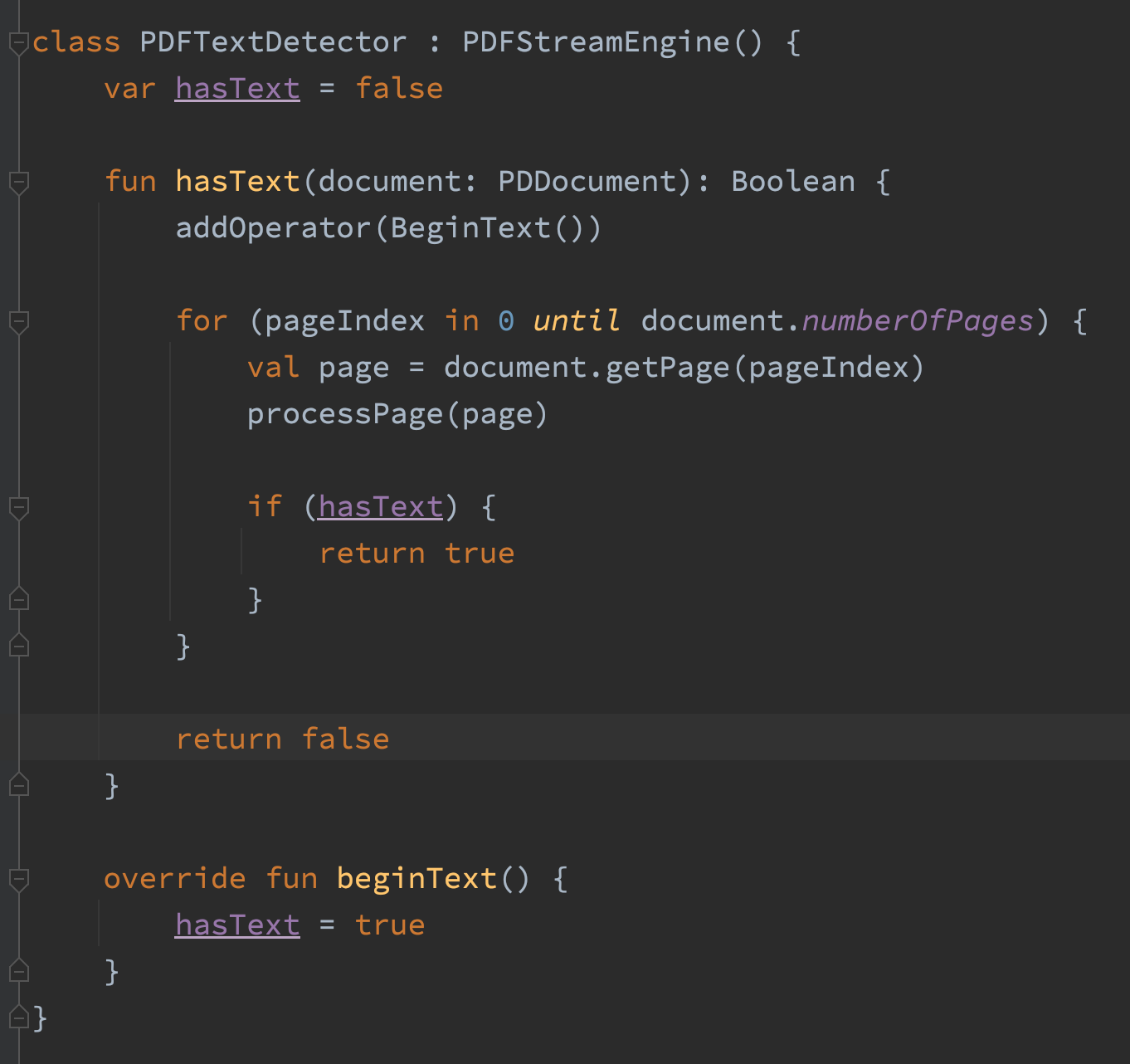
特性とバウンディング解析ストリップページで色、フォント、ローテーション、バウンディングボックスの為の全てのページ内の特性を戻す事が出来ます。アップロードの工程時に私が知らなければいけない情報は書面にテキストが存在するかです。コードが特性を発見すると「テキストが存在している」と認識し、そこで止まります。なので、その件に関してのクラスを書いてみました。
After that change the entire file upload route allocates 5 MB which means we’re allocating about 97% less memory than before. Good!

3. PDFからAPIへの変換の効率化
この効率化は素晴らしいもので、楽しみながらこの問題解決をする事が出来ました。銀行明細をPDFからエクセルへ変換したコードのプロファイラーを確認してみました。

getXRange() 法では232ページ分のPDFファイルで3311MB分配されました。コードを入れてもあまり効果が無かったので、これには私も驚きでした。
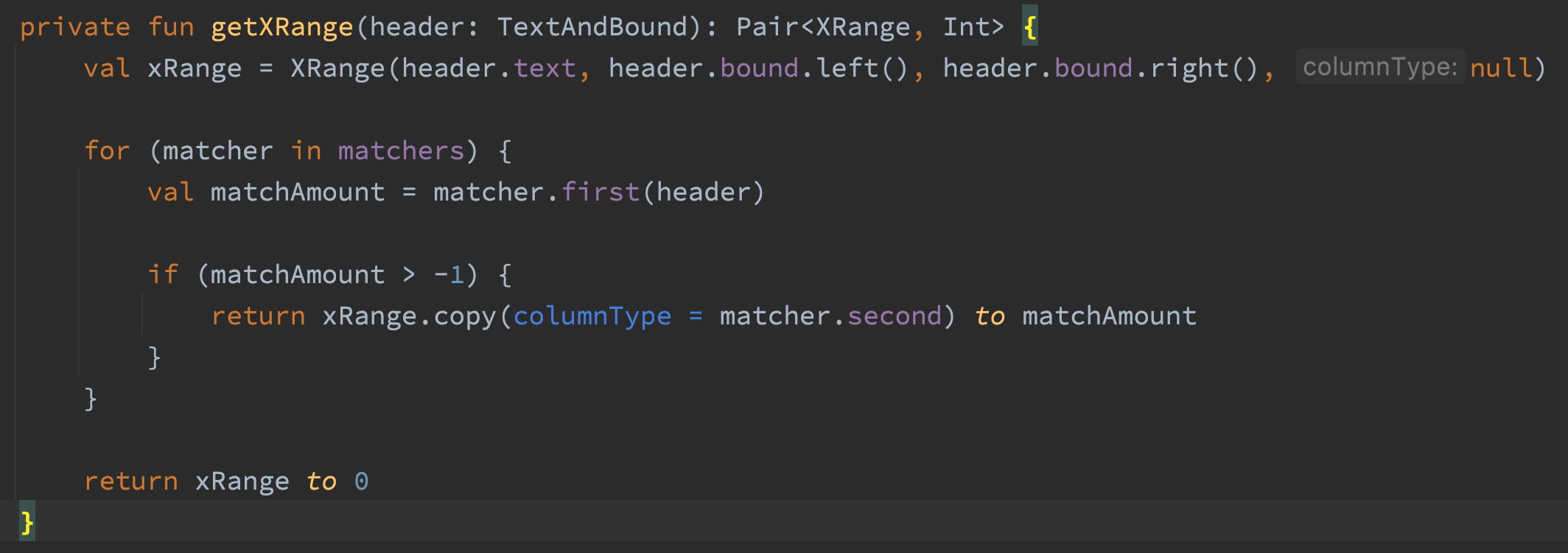
最初のコードのラインはXRange対象として作成されます。そのXRange対象は取引ヘッダーのテキストである場合のみ必要になります。そこで、私はテキストが適合した時のみXRangeを作成できる様なコードを作りました。そして、またプロファイラーを通しました。・・・まだ3311MB分配されています。いくつかXRangeで試してみましたが、メモリー使用量を減少させる事はできませんでした。 Quite a stumper! フレームグラフをもう少し確認してみると、getXRange内でのメモリ分配100%が照合の為でした。

Here’s the code for isEqualFromIndex()
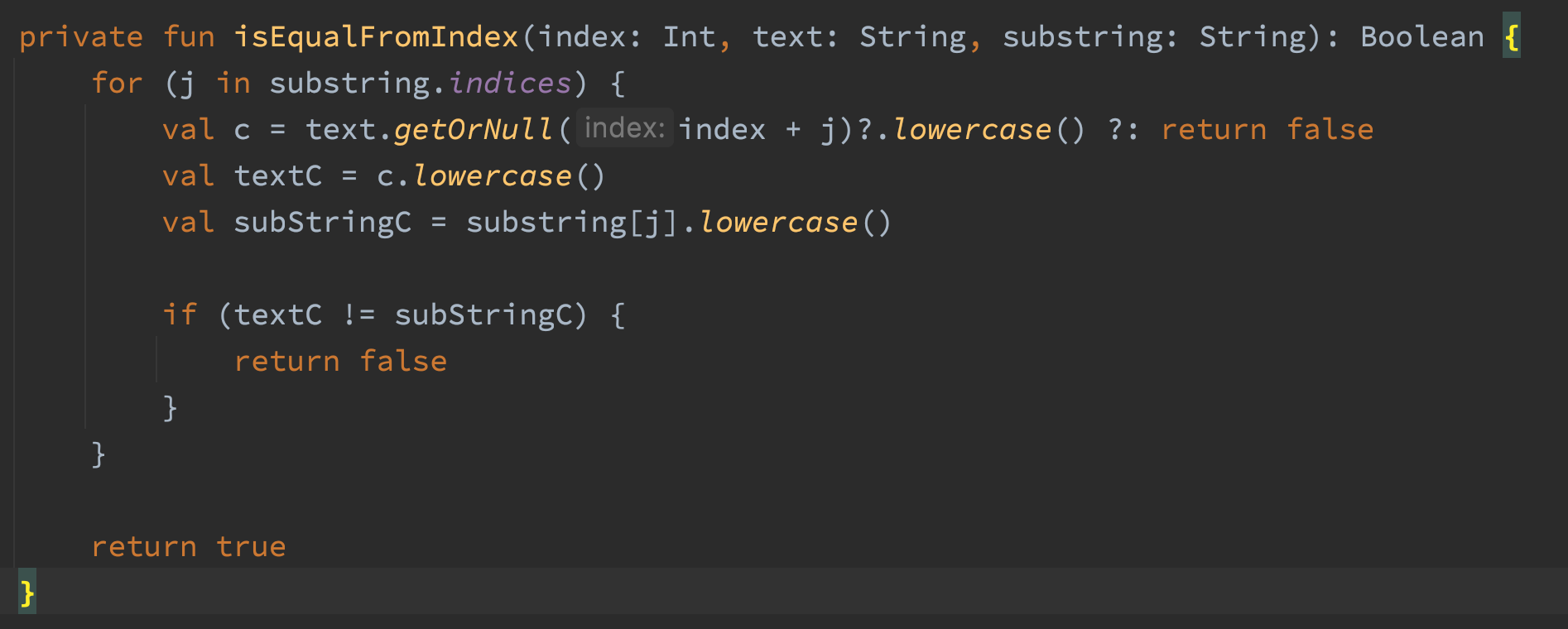
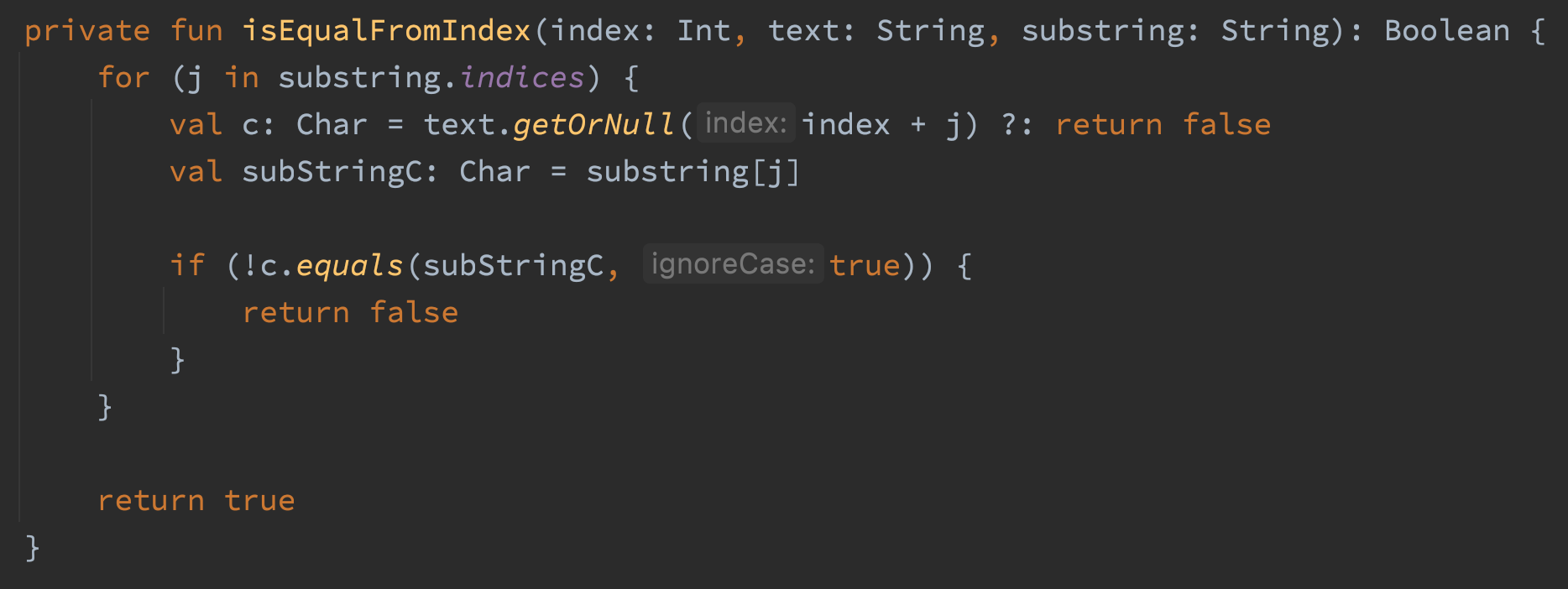
コードでオフセットを使い、ストリング内のサブストリングの照合が存在するかを確認しましたこの方法を書いた理由は、メモリを使う事無く、ストリング内で大文字小文字を区別しないサブストリングを探知できるか、という事だ。コードは使えますが、かなりのメモリが使われていあのです。小文字()の3つのコール法が怪しそうです。2コールなら十分らしいので、それ自体バカげていますね。他の問題は小文字() 法だとストリングが戻ってしまい、この方法内で3ストリング分配した事になります。気持ち悪いですね。これらの小文字 () コールを外して、Charsと比較してみましょう。
その後、getXRangeの分配を4 MBへ変えます。

この問題は楽しく解決する事が出来ました。ほんの少し変更しただけですし、修正にアプリの知識は全く必要ありません。.
4. 特性、バウンディングボックスの抽出の効率化
効率化 #2 では、特性とバウンディング解析ストリップページ ()にて大量のメモリが分配されている話しをしました。PDFテキストストリッパーの延長であり、これはレガシーストリームエンジン の延長で PDFストリームエンジンの延長でもあります。PDFテキストストリッパー と レガシーPDFストリームエンジンでは色々起きていますが、無くてもどうにかなると思っています急速な特性解析と呼ばれるクラスを作り、これは PDFストリームエンジンの延長でもあります。
プロファイリングを行った後、急速な特性解析でのメモリ量はかなり減少したのだが、テストケースを試してみるとテキストストリッパー と レガシーPDFストリームエンジンに重要な機能を付けるのを忘れていた為、ケーステストはうまくいかなかった。
**構成されている特性 **
テストスーツへ含めた一つの書面のコードは”Office”という言葉が6回コードされており‘﬒ (U+FB01) を使って"Ofï¬ce" と表示された。 特性. なぜこうなるのか分からないが、ユーザーはこれを望んでいないと思った。ノーマライザーのクラスを使って構成された特性をベース特性へ切り分けこの問題を解決する事ができた。
if (0xFB00 <= c && c <= 0xFDFF || 0xFE70 <= c && c <= 0xFEFF) {
normalized = Normalizer.normalize(c, Normalizer.Form.NFKC)
}
太字
いくつかの書面はテキストを太字にしたり、文字を2つ重ね二重にして、一つだけ少し左側や右側へずらしたりしているものもある。これは"Hello"の太文字だとコードでは"HHeelloo"となる。いくつかのテストではこのやり方でうまくいった。特性を位置で分別し、同じ又は似ている特性はフィルターを通し除去するやり方である。
急速特性解析の場合、特性とバウンディング解析と比較して20%程度使用メモリ量が少ない。 20%減とはかなりの量であるが、少し残念な結果だと感じた。
5. バウンディングボックスの計算の効率化
早急な特性解析の象形文字法で大きな書類を処理する場合、482MBのメモリが分配され、その内の381MBはAffineTransform.createTransformedShape() 法からの分配である。AffineTransformation はPDFの座標システムのフォントの変換に必要です。
// Before
var shape = at.createTransformedShape(rect)
shape = flipAT.createTransformedShape(shape)
shape = rotateAT.createTransformedShape(shape)
val bound = Rectangle.from(shape.bounds2D)
元々、3つのAffineTransformations を1つにして、 createTransformedShape を3回では無く1回でコールしようとしました。これを行う事で分配を381MBから130MBへ減少させる事が可能となるからです。それでもまだ分配が多すぎます。AffineTransform.java を確認してみると、この小さな嬉しい方法を見つける事が出来たのです。:
public void transform(float[] srcPts, int srcOff,
float[] dstPts, int dstOff,
int numPts)
これだとかなり軽くなります。その後、バウンディングボックスのフォントを2つに分け、変換法をコールし、バウンディングボックスを自分自身で計算しました。これがコードの結果です。
// Transform the rectangle
val buffer = floatArrayOf(rect.x, rect.y, rect.x + rect.width, rect.y + rect.height)
at.transform(buffer, 0, buffer, 0, 2)
flipAT.transform(buffer, 0, buffer, 0, 2)
rotateAT.transform(buffer, 0, buffer, 0, 2)
// Calculate the bounds of the transformed rectangle
val minX = Math.min(buffer[0], buffer[2])
val maxX = Math.max(buffer[0], buffer[2])
val minY = Math.min(buffer[1], buffer[3])
val maxY = Math.max(buffer[1], buffer[3])
val bound = Rectangle(minX, minY, maxX - minX, maxY - minY)
この結果、showGlyph 法の場合の分配は95 MBとなり、以前と比較し、387 MBも減少させる事が出来ました。
結果
Asyncプロファイラーはどのコードに多くのメモリが使われているのかのレポートを理解しやすくしてくれます。これが変わった事で、私のアプリも対応できる量がかなり変わったので、今まで以上の依頼を受ける事が出来る様になりました。アプリの交通量はそんなに多くないので、無駄な時間だったという方もいるかもしれませんが、私自身メモリ分配を低減させる事に喜びを感じながら対応する事が出来たので、それが一番重要な点だと思います。