Cinco formas en que manejé mis OutOfMemoryErrors
Posted on
Utilizo Grafana para crear gráficos que me muestran varias métricas comerciales y de rendimiento para Bank Statement Converter. Uno de los gráficos que creé rastrea la cantidad de errores Internal Server Errors que el servidor devuelve a los clientes. Hago esto escribiendo un registro en la base de datos cada vez que se envía un 500 al cliente. Este gráfico ha sido realmente útil para solucionar errores que no anticipé. El jueves pasado a las 12:55 AM HKT, mis servidores comenzaron a generar los infames errores OutOfMemoryErrors de Java.
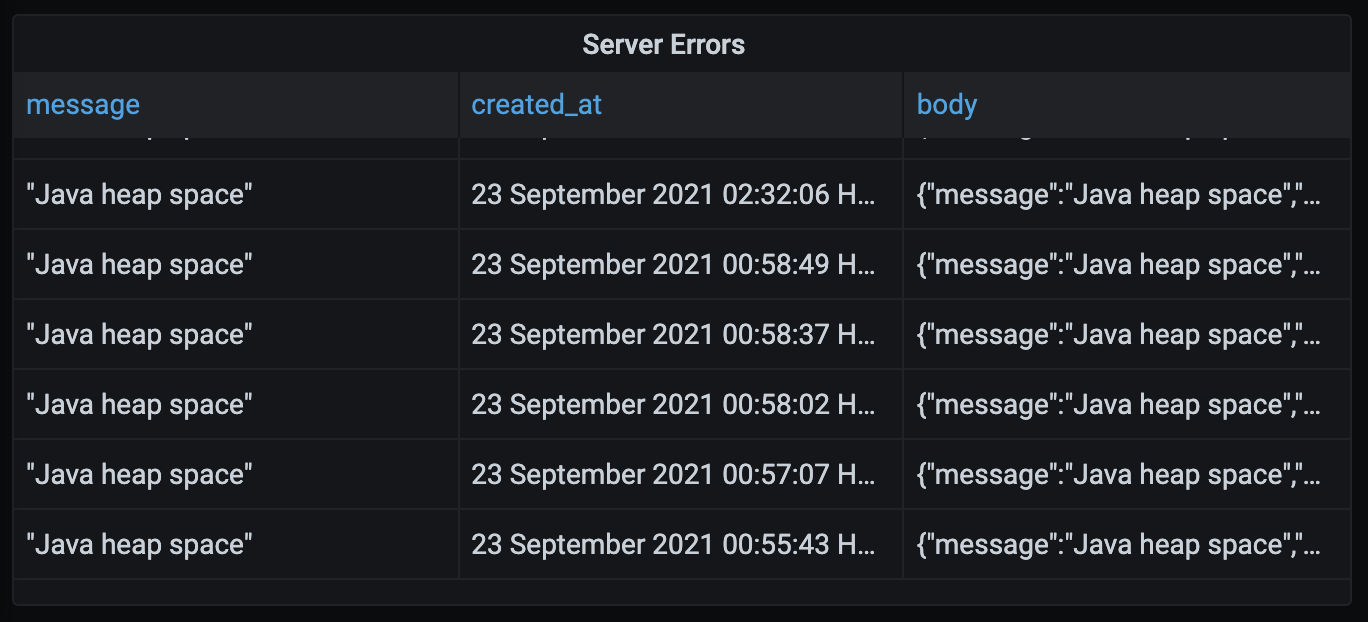
{
"message":"Java heap space",
"errorType":"UNKNOWN",
"cause":{
"type":"OutOfMemoryError",
"detailMessage":"Java heap space",
"stackTrace":[]
}
}
Hace unos meses encontré algunos de estos errores y los arreglé actualizando mis servidores de instancias de 1 GB a instancias de 4 GB. En ese entonces estaba usando tesseract en mis servidores para archivos PDF basados en imágenes OCR. Tesseract usa bastante RAM, así que pensé que necesitaría servidores con más RAM. Recientemente reemplacé tesseract con texttract de Amazon, por lo que ya no necesitaba RAM adicional para las imágenes de OCR. Cuando vi estos errores la semana pasada pensé “¿Me estoy quedando sin RAM en un servidor de 4 GB? Seguramente 4 GB son suficientes para procesar un archivo PDF”. Decidí optimizar mi código en lugar de lanzar más hardware al problema.
1. Solucionando un problema de interfaz de usuario
Cuando un usuario carga un PDF y presiona el botón de conversión, la interfaz de usuario se mueve a la página /converted. En esta página, la interfaz de usuario llama a una API que intenta detectar automáticamente los datos de transacción en el PDF. Si esa API no puede encontrar los datos de la transacción, la interfaz de usuario se mueve a la página /previewPDF. En esta página, el usuario puede seleccionar regiones para extraer. Aquí hay un pequeño error que causa la actividad en la imagen a continuación.
![]()
Las cuatro transacciones en la parte inferior muestran que el usuario llamó a la API de conversión cuatro veces en tres segundos. ¿Por qué haría esto? Me tomó un tiempo darme cuenta, pero finalmente me di cuenta de qué esto era lo que estaba pasando:
1. El usuario sube un PDF
2. El usuario presiona el botón Convertir
3. La interfaz de usuario lo lleva a la página /converted
4. La API dice que no puede detectar automáticamente las transacciones
5. La interfaz de usuario lo lleva a la página /previewPDF
6. El usuario presiona el botón Atrás, la interfaz de usuario lo lleva a la página /converted
7. Vaya al Paso #4
Básicamente, el usuario quiere volver a la página raíz, pero la interfaz de usuario finalmente lo lleva de regreso a la página previewPDF. La solución fue bastante fácil.
Antes
if (error.errorType === 'FAILED_TO_FIND_TRANSACTIONS') {
router.push('/previewPdf?uuids=' + uuid)
return
}
Después
if (error.errorType === 'FAILED_TO_FIND_TRANSACTIONS') {
router.replace('/previewPdf?uuids=' + uuid)
return
}
Esto reemplaza la última URL en la pila de historial con /previewPDF, y significa que el usuario es llevado a la página raíz en lugar de a la página /converted. Esto es una mejor experiencia para el usuario y también reduce la cantidad de llamadas API enviadas al servidor. Menos llamadas API significa menos uso de RAM y debería ayudar a reducir la frecuencia de OutOfMemoryErrors.
2. Optimización de la API de carga de archivos
Después de corregir la interfaz de usuario, quería reducir la cantidad de memoria asignada cuando se realizaban llamadas a la API. Lo primero que hice fue ir al entorno DEV y hacer clic frenéticamente en la interfaz de usuario para activar muchas llamadas a la API. Pude activar un OutOfMemoryError. Esta prueba es un poco injusta ya que los servidores DEV solo tienen 1 GB de RAM mientras que el servidor PROD tiene 4 GB. Curiosamente, pude detectar los errores al cargar un archivo. Eso fue sorprendente porque no sucede demasiado en la API de carga de archivos. Cuando se carga un archivo, sucede lo siguiente:
- El archivo se valida para asegurarse de que es un PDF
- El archivo se lee y se clasifica como TEXT_BASED o IMAGE_BASED. Esto se hace porque los documentos basados en imágenes deben ser tratados con OCR.
- Se crea un registro en la tabla file_mapping para vincular un uuid con un nombre de archivo
Tengo un caso de prueba para la API de carga de archivos, así que lo activé con Async Profiler habilitado. Al leer el informe, descubrí que mi controlador asigna 167 MB y el código que extrae el texto de un PDF asigna 144 MB. Esa es una cantidad ridícula de RAM.


CharacterAndBoundParser.stripPage() devuelve el color, la fuente, la rotación y los cuadros delimitadores de todos los caracteres de una página. En la etapa de carga, todo lo que necesito saber es si el documento tiene texto, una vez que el código encuentra un carácter, puede decir “sí, tiene texto” y luego detenerse. Así que escribí una clase que hace eso.
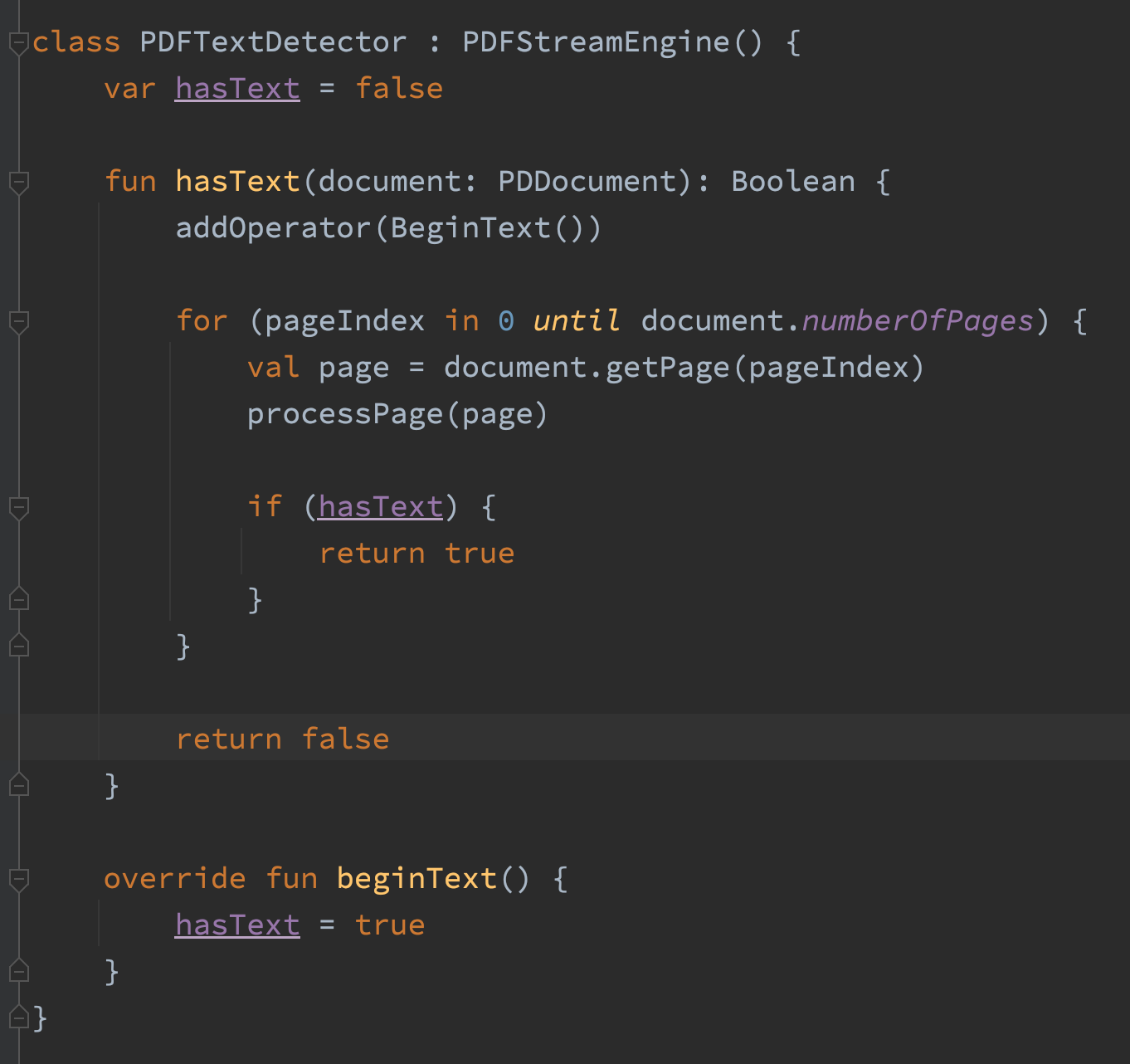
Después de ese cambio, toda la ruta de carga de archivos asigna 5 MB, lo que significa que estamos asignando aproximadamente un 97 % menos de memoria que antes. ¡Excelente!

3. Optimización de la API de conversión de PDF
Esta optimización es la mejor, realmente disfruté solucionar este problema. Ejecuté el generador de perfiles en el código que convierte un extracto bancario en PDF en un archivo de Excel y busqué grandes asignaciones.

El método getXRange() asignó 3311 MB al procesar un archivo PDF de 232 páginas. Esto me sorprendió porque el código no parecía estar haciendo mucho.
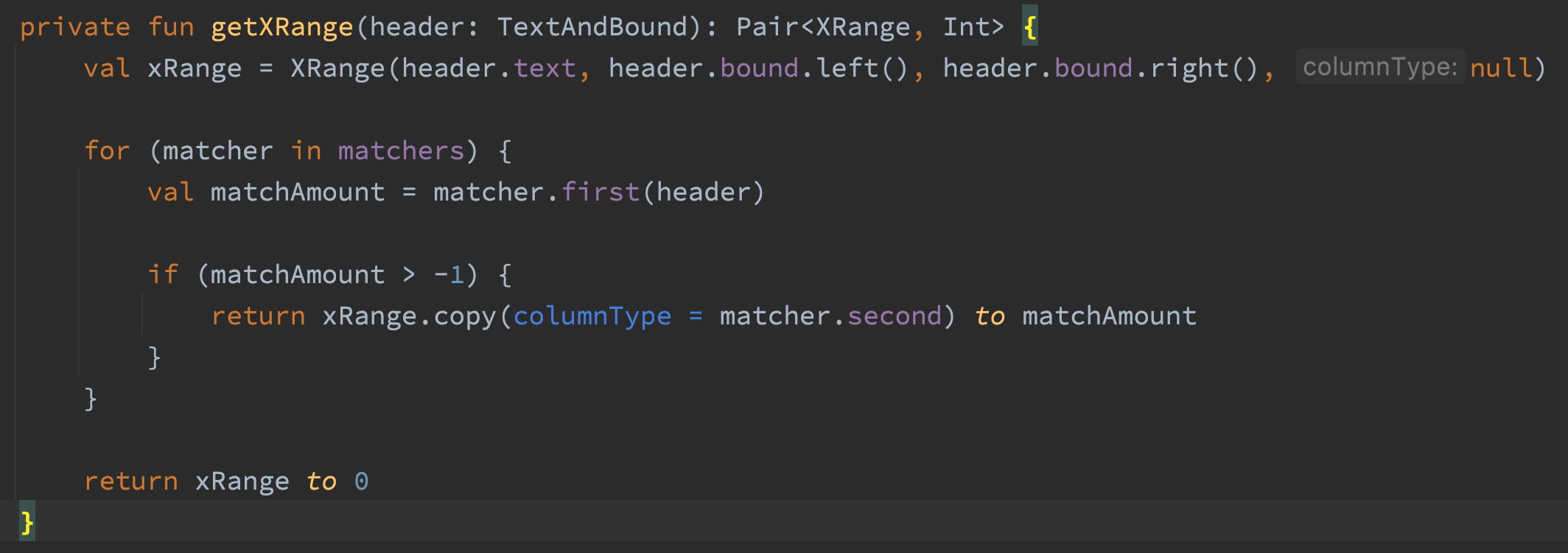
La primera línea de este código crea un objeto XRange. Ese objeto XRange solo es necesario si el texto es un encabezado de transacción. Así que cambié el código para crear solo el XRange si el texto coincide. Volví a ejecutar el generador de perfiles y… seguía asignando 3311 MB. Hice algunas cosas más para getXRange, pero nada pudo hacer que asignara menos memoria. ¡Qué estupidez! Observé un poco más el gráfico de llamas y descubrí que un método llamado por todos los emparejadores era responsable de 100 % de las asignaciones de memoria en getXRange.

Acá el código para isEqualFromIndex()
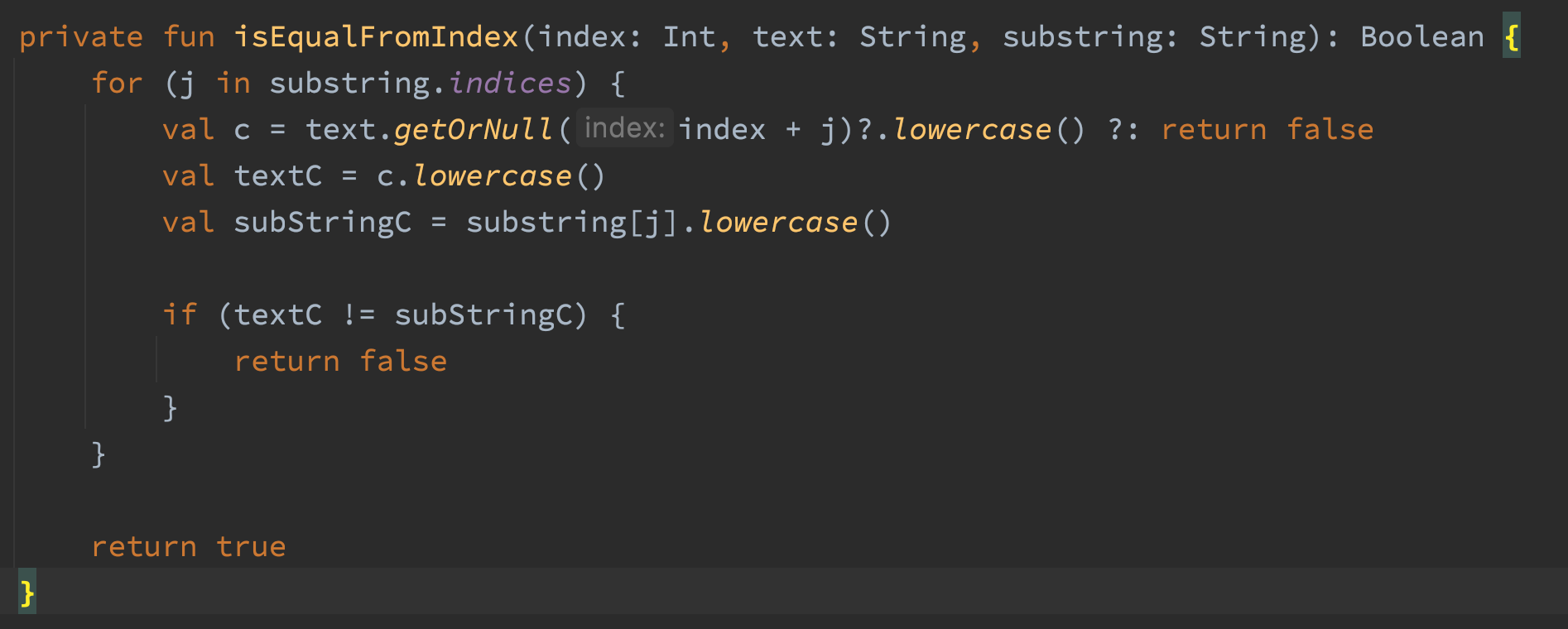
El código usa intervalos para verificar si existe una coincidencia de substring en un string. La razón principal por la que escribí este método es para detectar coincidencias de substrings que no distinguen entre mayúsculas y minúsculas en un string sin asignar memoria. El código funciona, pero estaba asignando toneladas y toneladas de memoria. Las partes con problemas del código son las tres llamadas al método lowercase(). Dos llamadas serían suficientes, así que eso ya es una tontería. El otro problema es que el método lowercase() devuelve un string, lo que significa que estamos asignando tres strings en el bucle de este método. Torpe. Eliminemos esas llamadas a lowercase() y hagamos la comparación con Chars en su lugar.
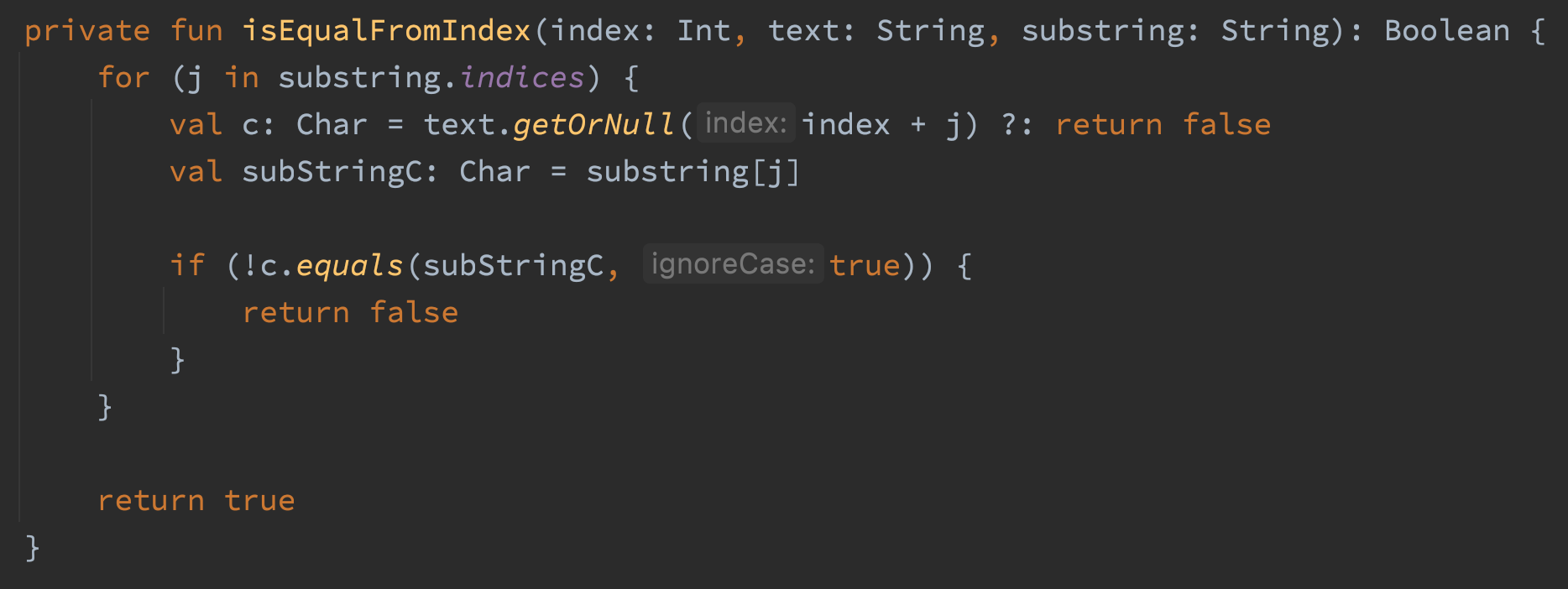
Después de ese cambio, getXRange asigna 4 MB

Realmente disfruté esta solución porque fue un cambio muy pequeño y no requirió ningún conocimiento de la aplicación para solucionarlo.
4. Optimización de la extracción de caracteres y cuadros delimitadores
En la optimización #2 aprendimos que CharacterAndBoundParser.stripPage() asigna mucha memoria. Extiende PDFTextStripper que extiende LegacyPDFStreamEngine que extiende PDFStreamEngine. Están sucediendo muchas cosas dentro de PDFTextStripper y LegacyPDFStreamEngine y sospeché que podría prescindir de él. Creé una clase llamada FastCharacterParser que solo extendía PDFStreamEngine.
Después de crear perfiles, entendí que FastCharacterParser asigna mucha menos memoria, pero mis casos de prueba fallaban porque me faltaba alguna funcionalidad importante en PDFTextStripper y LegacyPDFStreamEngine.
Caracteres compuestos
Uno de los documentos en mi conjunto de pruebas codifica la palabra de seis caracteres “Office” como cinco caracteres “Office” usando el carácter [‘fi’ (U+FB01)] (https://www.compart.com/en/unicode/ U+FB01). No tengo idea de porqué hace esto, pero probablemente no sea lo que el usuario quiere. Resolví esto usando una clase de Normalizador que divide los caracteres compuestos en sus caracteres base.
if (0xFB00 <= c && c <= 0xFDFF || 0xFE70 <= c && c <= 0xFEFF) {
normalized = Normalizer.normalize(c, Normalizer.Form.NFKC)
}
Texto en negrita
Algunos documentos muestran el texto en negrita duplicando el carácter y desplazándolo ligeramente hacia la izquierda o hacia la derecha. Esto significa que la versión en negrita del texto “Hola” en realidad se codificaría como “HHeelloo”. Algunos de mis casos de prueba muestran texto en negrita de esta manera. Resolví esto clasificando los caracteres por posición y luego filtrando los caracteres que son iguales y muy cercanos entre sí.
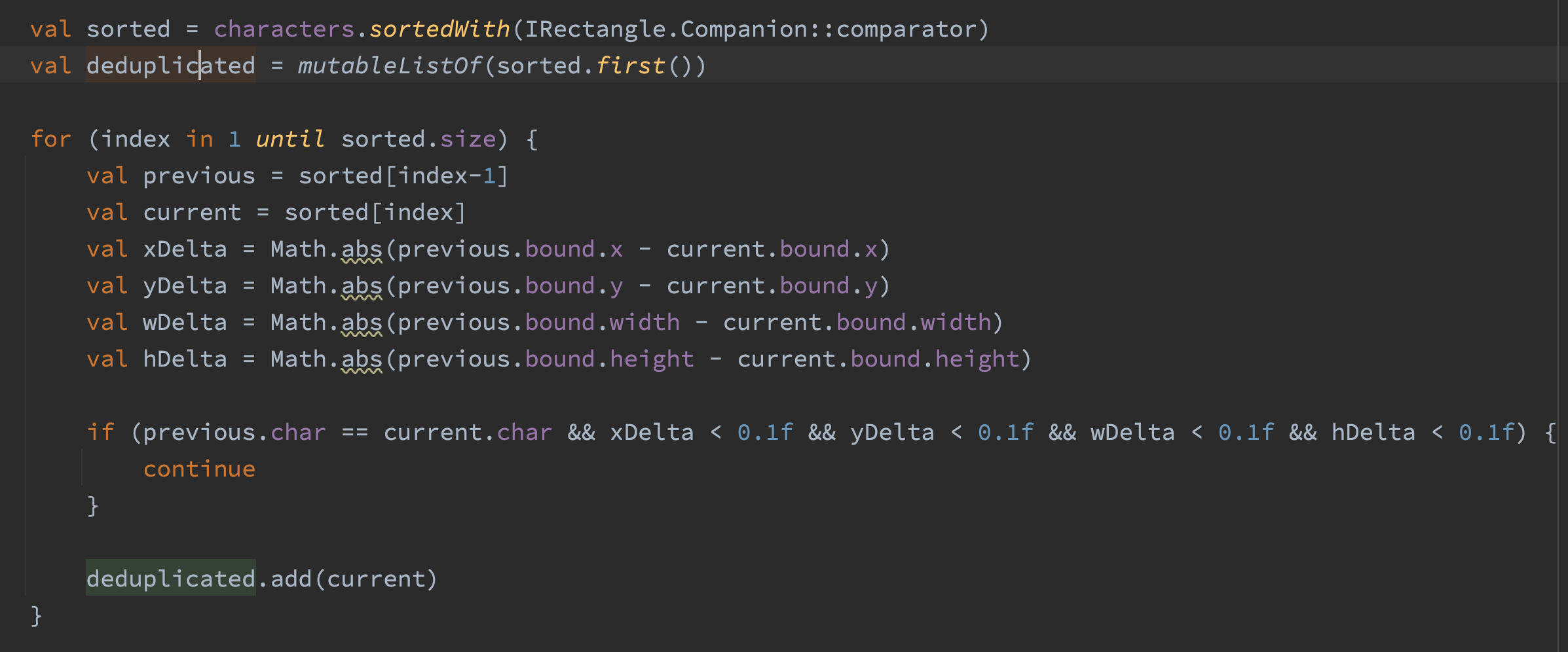
FastCharacterParser asigna un 20% menos de memoria en comparación con CharacterAndBoundParser. 20% es una reducción significativa, pero me decepcionaron un poco los resultados.
5. Optimización de los cálculos del cuadro delimitador
Al procesar un documento grande, el método showGlyph() de FastCharacterParser asigna 482 MB de memoria, 381 MB de esa asignación proviene del método AffineTransform.createTransformedShape(). Se necesitan AffineTransformation para transformar a del sistema de coordenadas de la fuente al sistema de coordenadas del documento PDF.
// Antes
var shape = at.createTransformedShape(rect)
shape = flipAT.createTransformedShape(shape)
shape = rotateAT.createTransformedShape(shape)
val bound = Rectangle.from(shape.bounds2D)
Inicialmente, pensé en convertir las tres AffineTransformations en una y luego llamar a createTransformedShape una vez en lugar de tres veces. Lo que debería reducir las asignaciones de 381 MB a alrededor de 130 MB. Sin embargo, eso sigue siendo una gran cantidad de asignaciones. Revisé AffineTransform.java y encontré este pequeño y feliz método:
public void transform(float[] srcPts, int srcOff,
float[] dstPts, int dstOff,
int numPts)
Esto se ve mucho más ligero. Luego dividí el cuadro delimitador de fuentes en dos puntos, llamé al método de transformación y calculé el cuadro delimitador yo mismo. Este es el código resultante.
// Transformar el rectángulo
val buffer = floatArrayOf(rect.x, rect.y, rect.x + rect.width, rect.y + rect.height)
at.transform(buffer, 0, buffer, 0, 2)
flipAT.transform(buffer, 0, buffer, 0, 2)
rotateAT.transform(buffer, 0, buffer, 0, 2)
// Calcular los límites del rectángulo transformado
val minX = Math.min(buffer[0], buffer[2])
val maxX = Math.max(buffer[0], buffer[2])
val minY = Math.min(buffer[1], buffer[3])
val maxY = Math.max(buffer[1], buffer[3])
val bound = Rectangle(minX, minY, maxX - minX, maxY - minY)
Esto da como resultado que el método showGlyph asigne 95 MB, que es alrededor de 387 MB menos que antes.
Conclusión
Async Profiler produce informes fáciles de entender sobre los métodos en el código que están asignando la mayor cantidad de memoria. Los cambios que hice han dado como resultado que mi aplicación pueda manejar muchas más solicitudes simultáneas que antes. Se podría decir que esto fue una pérdida de tiempo ya que mi aplicación no experimenta mucho tráfico simultáneo, sin embargo disfruté reduciendo las asignaciones de memoria y eso es lo más importante.