从PDF中提取文本和边界框
Posted on by Angus Cheng
这是我解释BankStatementConverter如何工作系列博客文章的第一部分。在这篇文章中,我将解释获取边界框和其他字符属性的代码。许多代码都是基于DrawPrintTextLocations和PDFTextstripper.
我们要做的第一件事就是使用PDFBox加载PDF文件,然后我们再逐页处理文档。我们需要逐页处理PDF,避免内存耗尽,大多数文档不到十页长,但也有超过10,000页长的文档,如果我们试图将一个大文档中的所有数据加载到内存中,我们会很快耗尽内存,我们的应用程序也会奔溃。我们使用parsePage方法提取页面上的所有字符,我们会得到一个CharAndBound对象列表。
data class CharAndBound(
val char: Char,
val bound: Rectangle,
val color: Int,
val fontCode: Int,
val rotation: Int
) : IRectangle by bound
FastCharacterParser
FastCharacterParser类的stripPage方法负责返回CharAndBound对象列表。它继承了pdfbox的PDFStreamEngine类并侦听以下事件:
private fun setOperators() {
addOperator(ShowText())
addOperator(BeginText())
addOperator(Concatenate())
addOperator(DrawObject())
addOperator(Save())
addOperator(Restore())
addOperator(NextLine())
addOperator(MoveText())
addOperator(MoveTextSetLeading())
addOperator(SetFontAndSize())
addOperator(ShowTextAdjusted())
addOperator(SetTextLeading())
addOperator(SetMatrix())
addOperator(ShowTextLine())
}
当PDFStreamEngine遇到字符,它将调用FastCharacterParser中的showGlyph方法,在这里我们会计算CharAndBound对象的所有属性。
override fun showGlyph(
textMatrix: Matrix,
font: PDFont,
code: Int,
displacement: Vector
)
我们可以使用textMatrix参数来确定字符在页面上的角度和位置。我们使用字体的边界框来确定字符的宽度和高度。有些字体没有边界框信息,当我们遇到这种情况,我们选择回退到硬编码的边界框,并希望最终结果不会出错。
val bbox = getBoundingBoxWithHackyFallback(font)
// 设置步进宽度, bbox 高度 (字符空间)
val xAdvance = font.getWidth(code)
val rectangle = Rectangle2D.Float(0f, bbox.lowerLeftY, xAdvance, bbox.height)
到目前为止,我们有一个Rectangle2D,但它是在“字符空间”内而不是在“文档空间”,你可以看到上面有一个明显的问题,即x坐标被硬编码为了0F。下一步是将此矩形从字符空间转换为文档空间。
val affineTransform = textMatrix.createAffineTransform()
// 转换长方形
val buffer = floatArrayOf(rectangle.x, rectangle.y, rectangle.x + rectangle.width, rectangle.y + rectangle.height)
affineTransform.transform(buffer, 0, buffer, 0, 2)
flipAT.transform(buffer, 0, buffer, 0, 2)
rotateAT.transform(buffer, 0, buffer, 0, 2)
// 计算转换后的长方形边界值
val minX = min(buffer[0], buffer[2])
val maxX = max(buffer[0], buffer[2])
val minY = min(buffer[1], buffer[3])
val maxY = max(buffer[1], buffer[3])
val bound = Rectangle(minX, minY, maxX - minX, maxY - minY)
上面的AffineTransformation是根据页面的旋转角度和页面的高度配置的。PDF定义的原点为页面的左下角,而我更喜欢以左上角作为原点,因此我用flipAT执行变换。类似地,rotateAT负责向字符的边界框添加页面旋转信息。大多数文档的旋转度为0,但横向文档的旋转度通常为90或270度。现在页面上有了字符的边界框。接下来,我们需要弄清楚这个字体代码代表什么字符。
var unicode = font.toUnicode(code, glyphList)
if (unicode == null) {
if (font is PDSimpleFont) {
val c = code.toChar()
unicode = String(charArrayOf(c))
} else {
return
}
}
unicode = normalizeWord(unicode)
首先,我们尝试从字体中获取fontCode的字符。如果失败了,且字体是SimpleFont,我们便假设字体的代码是unicode,只需将其转换为字符即可。normalizeWord方法负责分解组合字符的基本部分。字符“ff”在UTF16中编码为FB00,normalizeWord将其分解为两个“f”字符并返回字符串“ff”。
if (unicode.length == 1) {
characters.add(CharAndBound(unicode.first(), bound, rgb, fontCode, rotation))
return
}
val startX = bound.left()
val width = bound.width / unicode.length
for (index in unicode.indices) {
val x = startX + (index * width)
characters.add(CharAndBound(unicode[index], bound.copy(x = x, width = width), rgb, fontCode, rotation))
}
通常由characterCode形成的字符串长度为1。如果是这种情况,我们可以生成一个CharAndBound,并将其添加到字符列表中。然而,如果我们遇到像“ff”这样的组合字符,unicode将是“ff”且长度为2。上面的代码在字符串中的字符之间共享同一个边界框。例如,假设“ff”有一个[0,0,120,30]的边界框,在拆分后,第一个“f”将有一个[0,0,60,30]的边界框,第二个“f”将有一个[60,0,60,30]的边界框。这段代码不适用于垂直文本,但对于我的使用范围内似乎并不会遇到这个问题
现在让我们看看它在实践中表现如何,我在网上找到了此PDF,提取边界框,然后将它们渲染到每一页上。看起来这个精度对于我们的使用范围来说没有问题。

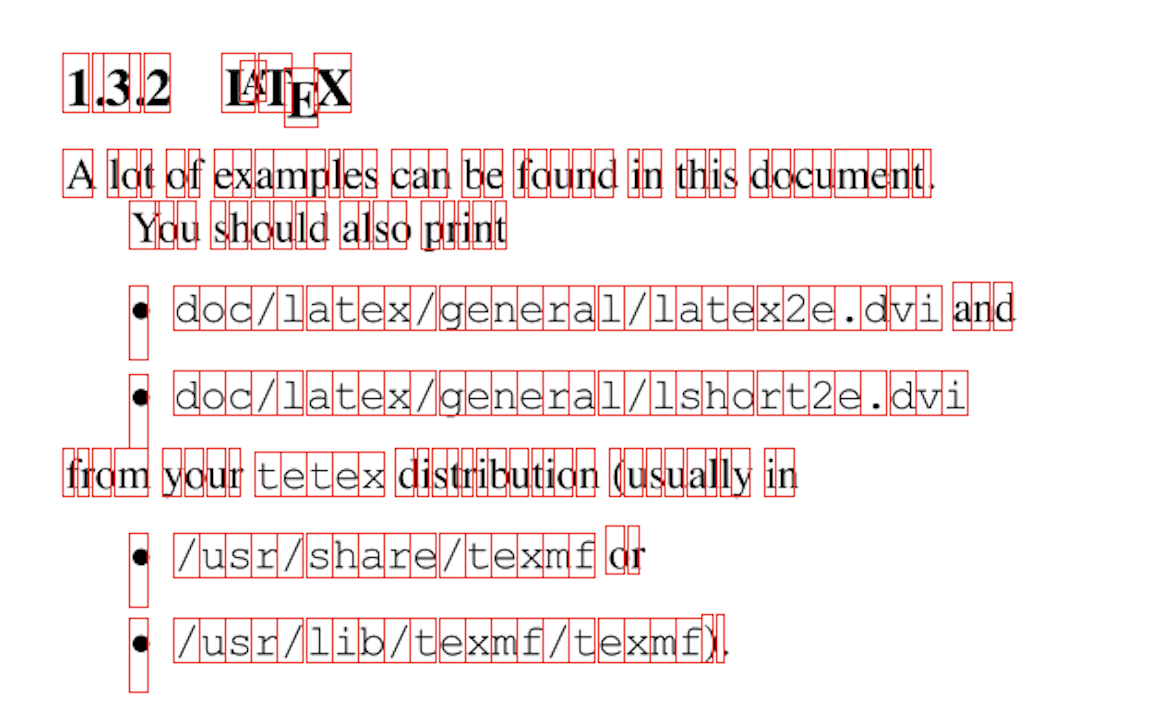
在下一篇文章中
在系列的第二部分,我们将讨论如何使用CharAndBound列表来确定转账表的头。